Executive Summary
Red Hat strategically provides consistency wherever you run inference. The effort you invest in building solutions can be adapted to the landing zone for public cloud, on‑prem, or edge and optimized for the specific hardware and adjacent systems available there. Token‑based services let you move quickly, but the provider retains the margin between the token price and the ever‑improving hardware underneath. When you control the stack, you keep that margin and can continuously tune performance, cost, and compliance to your advantage.
The emergence of large language models (LLMs) like Deepseek‑V3, LLaMA 3, Falcon, and DeepSeek‑R1 has ushered in a new era of AI‑driven enterprise innovation. These models have demonstrated extraordinary potential across domains ranging from customer service and finance to healthcare and scientific discovery. Yet the technical requirements for deploying LLMs at scale are anything but ordinary.
Today’s LLMs routinely exceed tens or even hundreds of billions of parameters, demanding massive computational throughput and high‑bandwidth, low‑latency memory access. For business and IT leaders, this translates into mounting operational complexity, unpredictable latency, soaring GPU costs, and resource constraints that can stall production deployments
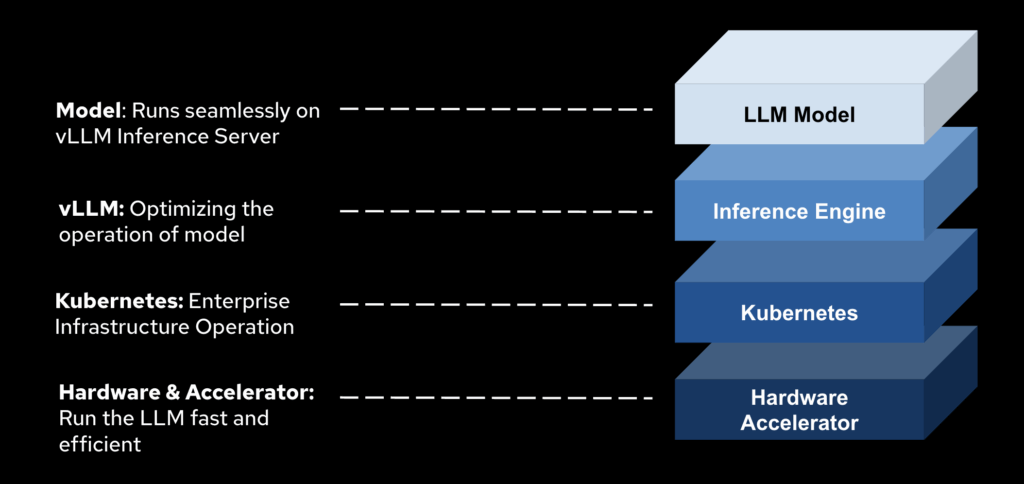
This paper introduces a strategic solution: vLLM, an optimized LLM inference engine, paired with Red Hat OpenShift AI, a secure, scalable, enterprise‑grade platform. Together, they provide a complete foundation for deploying LLMs across hybrid cloud, on‑premises, and multi‑tenant environments without compromising performance, accuracy, or security.
1. The Modern Hardware Landscape and What LLMs Demand
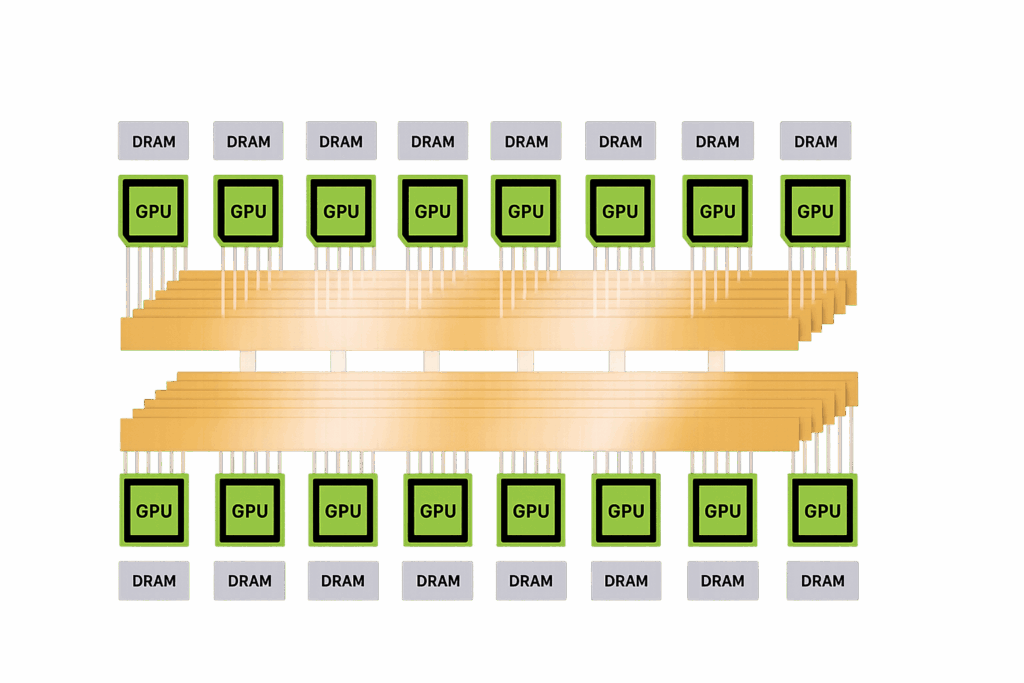
Modern GPUs—such as NVIDIA’s A100, H100, and B200 are designed with AI in mind. They feature:
- Tensor Cores optimized for FP16/BF16
- High Bandwidth Memory (HBM) up to 8 TB/s
- NVLink for fast GPU-GPU communication
- Multi-Instance GPU (MIG) capabilities for resource partitioning
Yet despite these advancements, the largest LLMs (e.g., LLaMA 405B, Deepseek-V3-Large) cannot run efficiently on a single GPU or server. Models at this scale may require hundreds of GB of VRAM, which even the best GPUs cannot handle without advanced orchestration, model sharding, and memory optimization.
These challenges are compounded by the fact that LLM inference is both memory-bound and compute-bound. The attention mechanism in transformers scales quadratically with sequence length, and caching past tokens for multiple users quickly exhausts GPU memory, even before the model weights are loaded.
2. Why Legacy Serving Approaches Fall Short
Enterprises trying to serve LLMs on legacy inference stacks often encounter:
- Out-of-memory errors from inefficient KV cache management
- Low GPU utilization due to static batching and underloaded cores
- Latency spikes from serialized token generation
- Operational friction managing distributed model shards and multi-GPU workloads
As models grow in complexity and deployment scenarios diversify (e.g., real-time chat, document summarization, retrieval-augmented generation), these limitations become showstoppers. Without a modern, purpose-built runtime, organizations are forced to make trade-offs between speed, cost, and quality.
3. Why Multi-GPU and Multi-Node Inference is Essential
No single GPU can accommodate today’s largest models in full precision. To retain accuracy, especially in mission-critical applications, multi-GPU and multi-node inference is essential.
Key architectural strategies include:
- Tensor Parallelism: Splitting computations within a layer across GPUs
- Pipeline Parallelism: Assigning different layers to different GPUs
- Expert Parallelism: Activating only the necessary model experts (in MoE models)
- Sequence Parallelism: Processing batch elements across devices
These techniques unlock scalability but require tight GPU-GPU coordination, cache synchronization, and workload-aware scheduling—capabilities that traditional inference systems do not natively support.

4. Introducing vLLM: A High-Performance Inference Engine
vLLM is a next-generation LLM serving engine designed from the ground up to solve the efficiency, throughput, and scalability challenges of transformer inference. Key architectural features include:
- PagedAttention: A memory-efficient attention mechanism that organizes KV cache into pageable memory blocks. Result: 2–3× more users per GPU.
- Unified KV Cache: Shared cache blocks across sequences with dynamic allocation and reclamation.
- Continuous Batching: Real-time token-level batching, reducing latency and maximizing GPU utilization.
- Prefix Caching: System prompts and templates are computed once and reused, saving memory and compute.
- Mixed Parallelism: Seamless support for tensor, pipeline, and sequence parallelism.
Together, these innovations allow vLLM to deliver superior performance at a significantly lower cost.
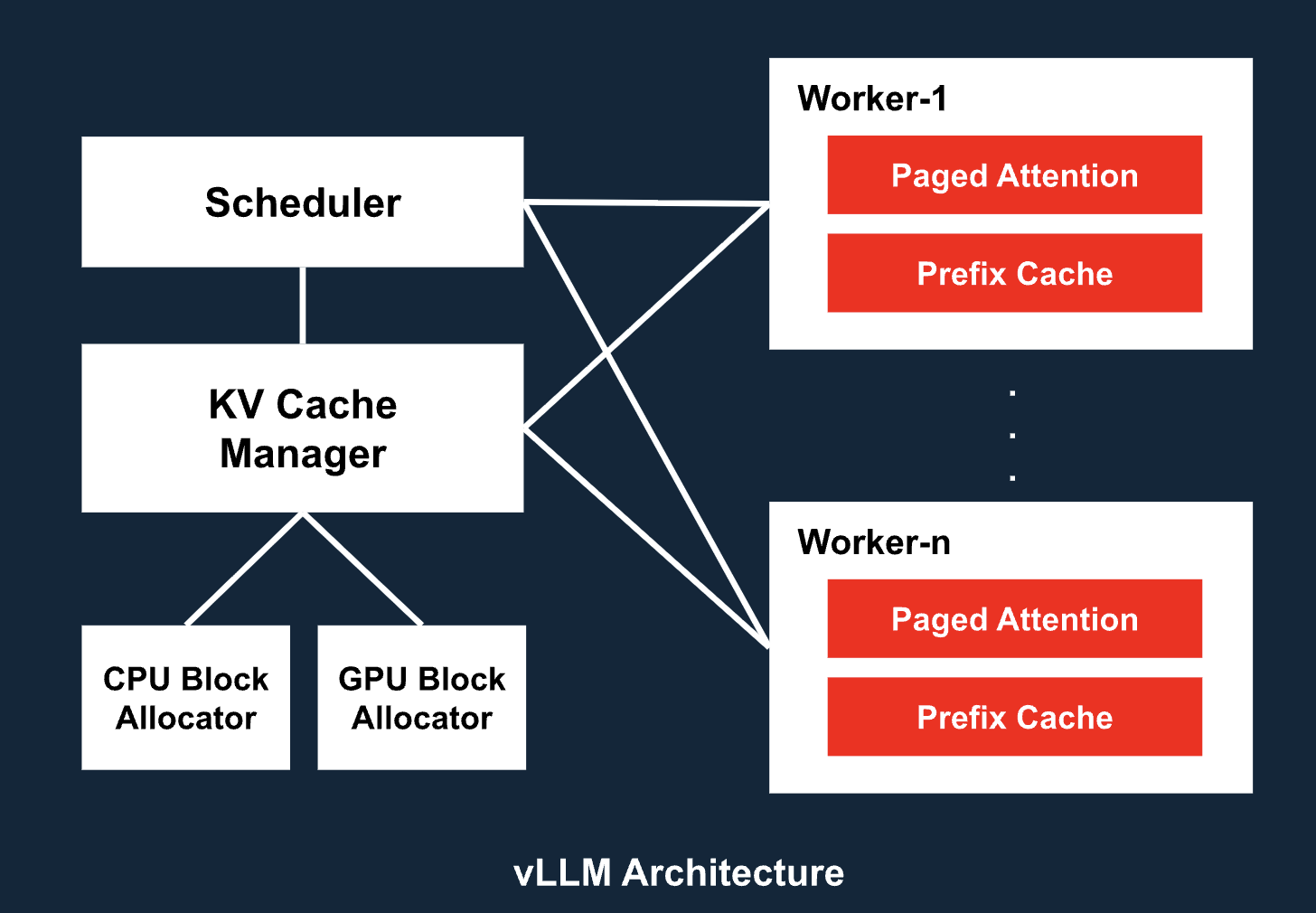
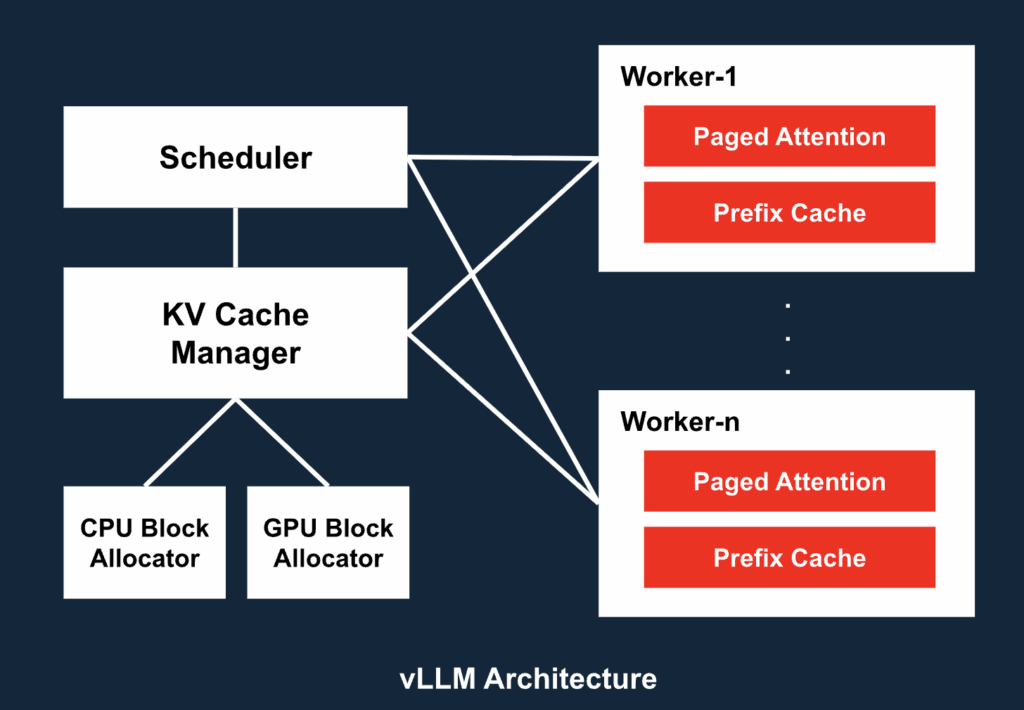
5. vLLM System Architecture: Engineered for Scale
The vLLM system is composed of several modular, scalable components:
- API Server: OpenAI-compatible HTTP interface
- Engine Core: Coordinates scheduling, caching, and execution across components
- Scheduler: Token-level batching engine for mixing requests dynamically
- KV Cache Manager: Tracks memory block usage across GPU and CPU
- Paged Attention: Efficient attention mechanism using paged memory blocks for scalability
- Prefilled Context Cache: Caches prompt prefixes to avoid redundant computation
- Parallelism Layer: Manages tensor, pipeline, and model parallelism across devices
- Worker Nodes: Each runs a cache engine and model shard on a dedicated GPU
This architecture allows vLLM to serve models with tens of billions of parameters across distributed GPU fleets, while maintaining low latency and high throughput.
6. vLLM & Compression: Unlocking Efficiency Without Sacrificing Accuracy
As large language models continue to grow in size—reaching hundreds of billions of parameters—the need for model compression becomes critical. Compression techniques such as quantization, sparsity, pruning, and weight sharing offer a way to dramatically reduce memory usage and inference costs, but most inference engines either fail to support them fully or require trade-offs in accuracy, latency, or ease of use.
Key Benefits of vLLM with Compression:
- Seamless Quantization Support: vLLM supports int8 and 4-bit quantized models out-of-the-box (e.g., QLoRA, AWQ, GPTQ), retaining near-original model accuracy with substantial memory savings.
- KV Cache Compression: By reducing the memory footprint of cached key-value pairs, vLLM extends the number of concurrent sessions that can be served per GPU.
- Reduced Memory Bandwidth Pressure: Compressed weights mean faster fetches from GPU memory, leading to smoother token generation and reduced tail latency.
- Compatibility with Distilled Models: In addition to quantization, vLLM serves smaller distilled versions of large models, ideal for cost-sensitive and latency-critical use cases.
Business Impact:
Compression enables serving 40–70B parameter models on commodity GPUs or even deploying multiple smaller LLMs per MIG slice—something previously infeasible. This dramatically lowers the total cost of ownership (TCO) while preserving the flexibility to serve a wide range of workloads, from chatbots and copilots to RAG pipelines and multi-turn agents.
7. Why Kubernetes Complements vLLM Perfectly
Kubernetes provides the operational foundation needed to run vLLM in secure, enterprise environments:
- Containerized Inference at Scale: vLLM models run inside Red Hat-certified containers
- MIG-aware GPU Scheduling: Assign multiple LLM workloads per GPU slice
- CI/CD for Model Lifecycle: Automate promotion from testing to production
- Security and Compliance: Leverage RBAC, SSO, and audit trails
- ModelMesh Integration: Serve multiple LLMs on-demand from shared GPU pools
- Observability: Use Prometheus, Grafana, and Red Hat Insights to track performance and usage
Whether you’re deploying on-prem, on OpenShift Service on AWS (ROSA), or hybrid cloud, OpenShift AI brings reliability, governance, and operational excellence to LLM inference.

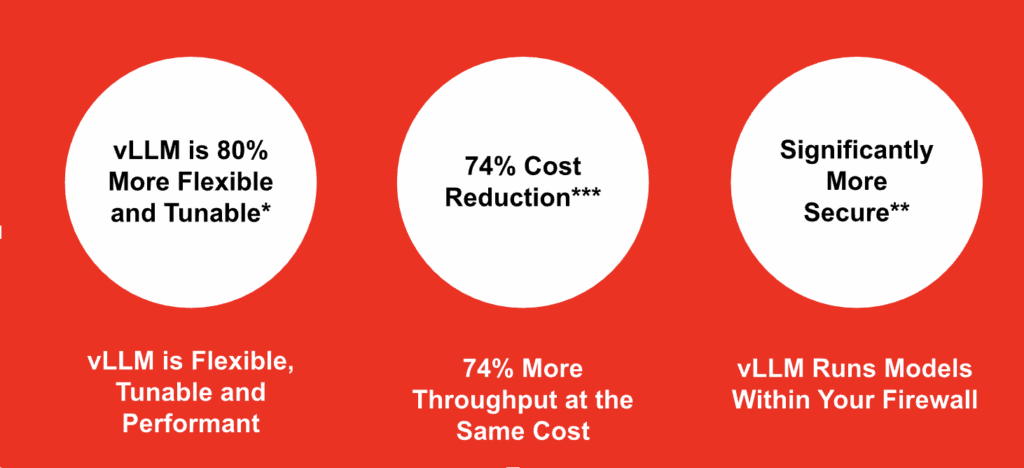
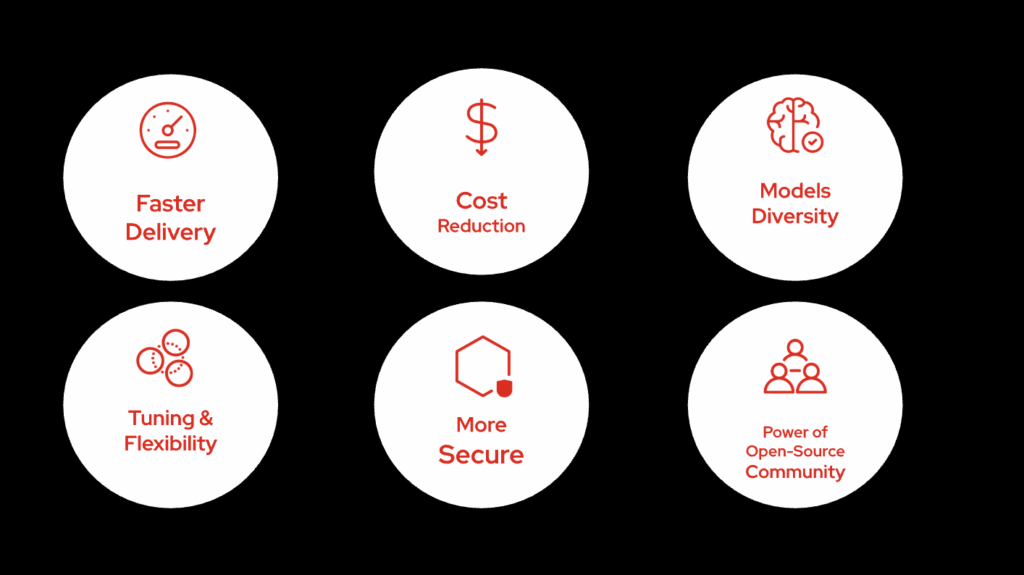
8. Measurable Business Impact
vLLM + Red Hat OpenShift AI delivers tangible, enterprise-scale value:
- Up to 74% lower infrastructure cost per throughput unit by running self-managed models efficiently
- 2–4× GPU utilization gains via kv-cache, advanced batching, and memory optimizations
- Consistent low-latency performance across diverse inference workloads
- Access to all leading LLMs as-a-service, enabling faster development of intelligent applications
- Over 80+ fine-tuning and compression parameters, giving teams precise control over model behavior, memory use, and runtime cost
- Enterprise-grade security and compliance for financial, healthcare, and public sector deployments
- Expansive open-source community support, accelerating innovation, troubleshooting, and ecosystem integration
Together, vLLM and OpenShift AI enable faster time to value, lower TCO, and scalable, secure deployment of LLM-powered applications.
9. Adoption Roadmap
Phase 1: Proof of Concept
- Deploy vLLM container with LLaMA 13B or Mistral 7B on OpenShift AI
- Benchmark performance and GPU efficiency
Phase 2: Pilot Deployment
- Scale to multi-node
- Integrate ModelMesh for dynamic model routing
- Enable observability, SSO, and role-based access control
Phase 3: Enterprise Production
- Serve 70B+ models with MIG partitioning
- Automate with CI/CD pipelines
- Secure endpoints and scale via autoscaling
Conclusion
Enterprises are rapidly moving from experimentation to operational AI. However, LLMs at scale demand architectural precision, performance optimization, and enterprise integration.
vLLM provides breakthrough performance. Red Hat OpenShift AI provides the operational foundation. Together, they enable scalable, efficient, and secure deployment of LLMs in real-world production environments.
Leave a Reply to Ben Hajian Cancel reply